Building Tweet Collector with GPT-4
In all the hype, I also bought GPT-4 subscription, and decided to make an experiment: I will guide GPT to fully develop a production-ready system for one of my needs.
The system is rather simple:
- It will query Twitter API with a given search query, then store all new tweets to the database
- When run next time, it does the search again, and continues to collect tweets from the last one.
First, I write a somewhat detailed description of what my program should achieve, including details about the db structure and which libraries I want it to use:

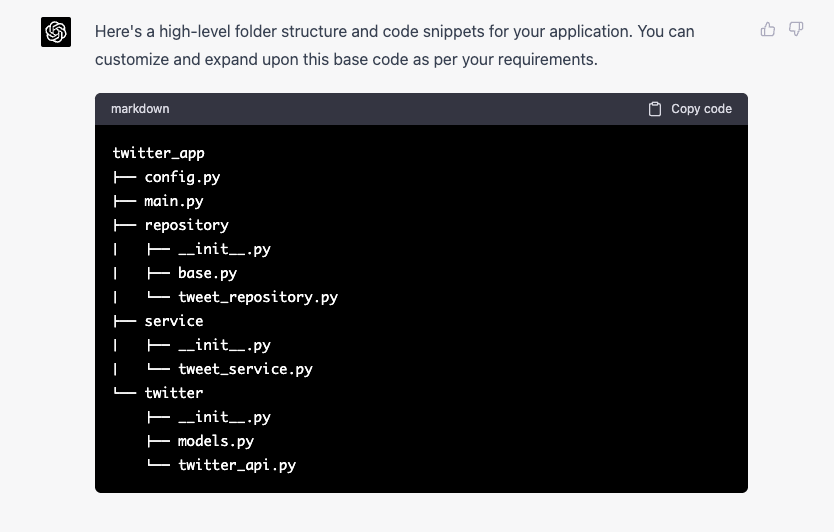
Project structure looks reasonable enough:
First problem I notice is a technical one, it still cannot generate outputs longer that a certain amount of tokens, and abruptly stops, so I have to ask for each file separately:
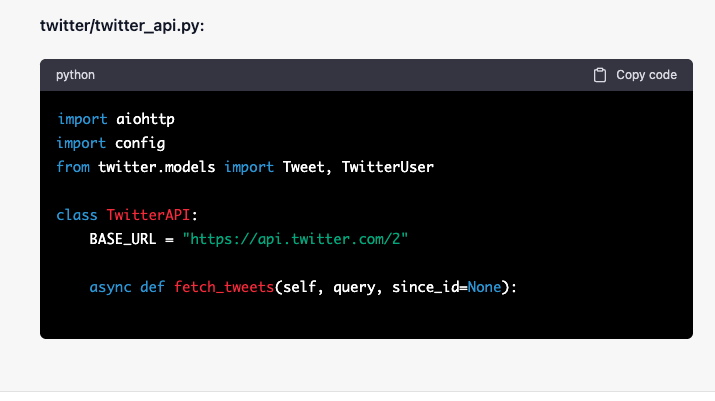
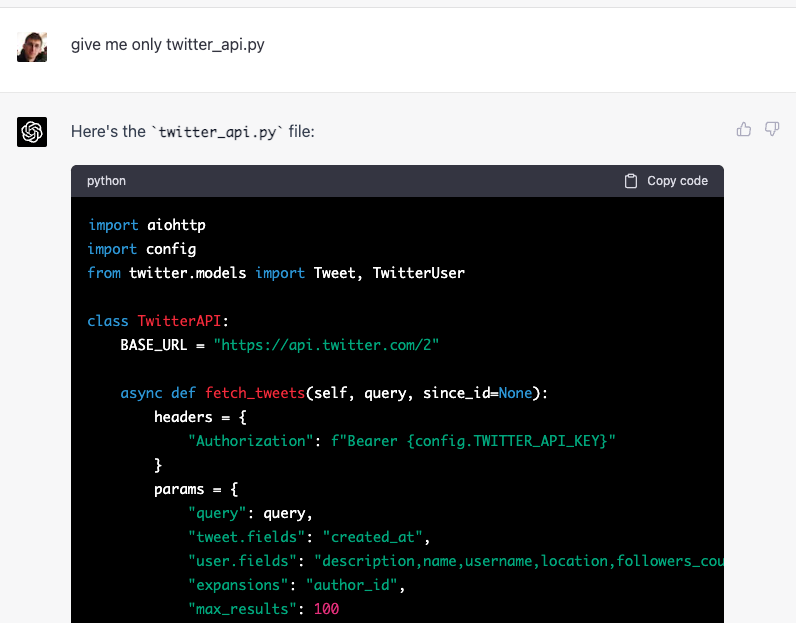
Now, I already have some template for such "fetch some data from an API" projects, and it is just much easier for me to work with them, so I take some time to integrate what GPT-4 has generated into it, but don't change any internal logic.
Twitter API
The code didn't work right away, here are the errors that it made in order of discovery when running the code:
-
It requested two non-existing fields in
user.fields–followers_countandtweet_count. These fields exist insidepublic_metricsobject. GPT-4 correctly fixed this bug when requested. -
locationattribute is not present for all users, so it needs to use.get("location")instead of["location"]
I was now able to see the tweets coming in the debugger.
Data storage
In the data storing part, I found two issues:
- Twitter users might not be unique, and generated code didn't check for it and put them into list. It was able to correct it, although not from the first attempt.
- Tweets and users are stored within a single transaction, and storing them as separate lists results in an error if some users do not exists in the database. A simple solution is to break a transaction into two parts, another is to attach tweet users to each tweet as objects.
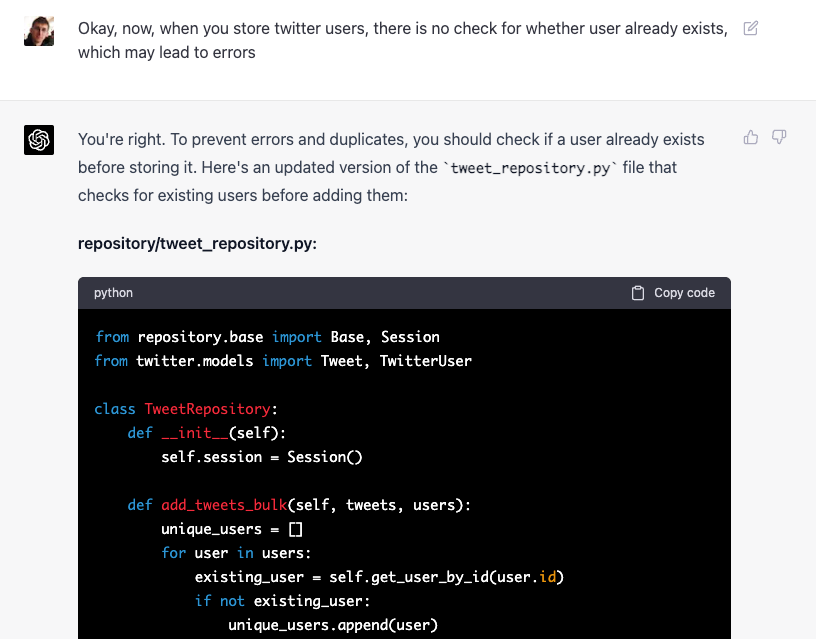
In the end I have changed the workflow a bit myself, and made users a dictionary that is collected like this from the API, such that we don't need to check the list for duplicates.
After fixing this issue, the program completed successfully and stored tweets and users in the database.
Code quality and performance
In terms of code quality, I noticed several things that could be improved:
- Generated code does not have proper dependency injection and instantiates dependencies from scratch in constructors
- Generated DB models do not have
nullableattributes to see whether fields can be null verifiedcolumn is generated as integer column instead of bit.- Tweets are stored in db one by one, and the check for user existence is also performed one by one with one query per id.
- To get the last tweet id, it retrieves the whole model from db, not just the id
However, it was able to correct all these issues when asked:
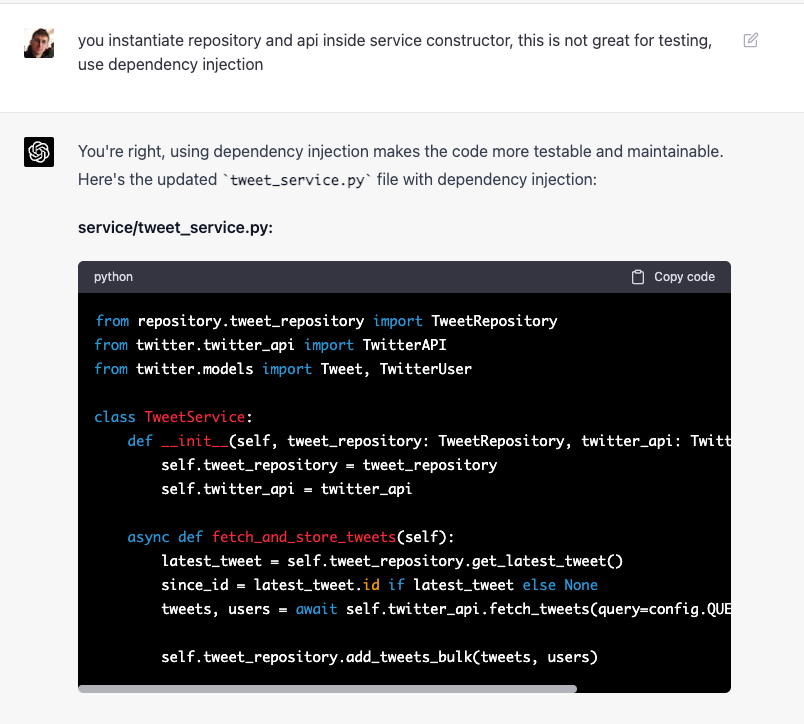
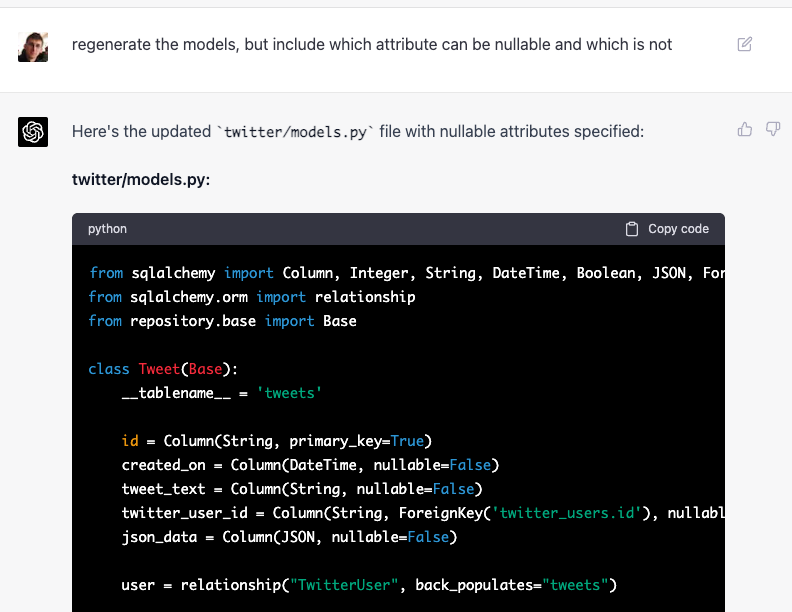
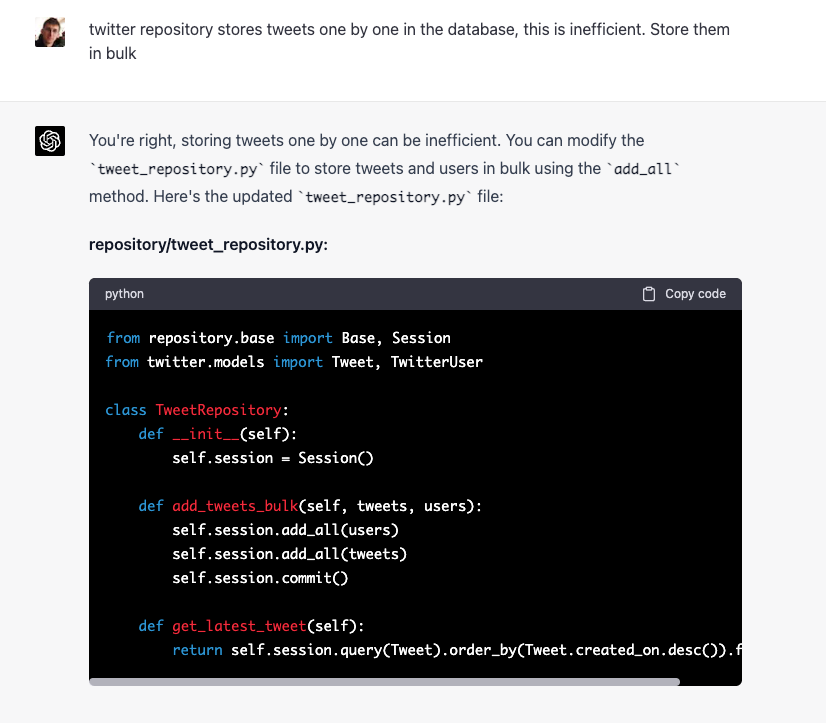
I only fixed a couple of small issues described above.
Pluses:
- When asked for changes, it understood everything and provided proper corrections
- When asked for a change, only presents you with the parts of code that need to be modified instead of re-generating whole files
Minuses:
- Not consistent in outputs – when asked to regenerate the answer from scratch, it can produce significantly different project structures.
- Overall project code structure is average at best
- Many errors in the logic that need to be corrected manually
- Have to manually ask to correct small things that only an experienced software engineer can notice, GPT-4 seem to repeat these small things in certain patterns, like requesting whole model from the db